Machine details: gottardo-ht
Machine: gottardo-ht
CPU: Intel(R) Xeon(R) CPU L7555 @ 1.87GHz
Number of cores: 64
NUMA configuration: 4x16
Topology Information
TODO: likwid input here
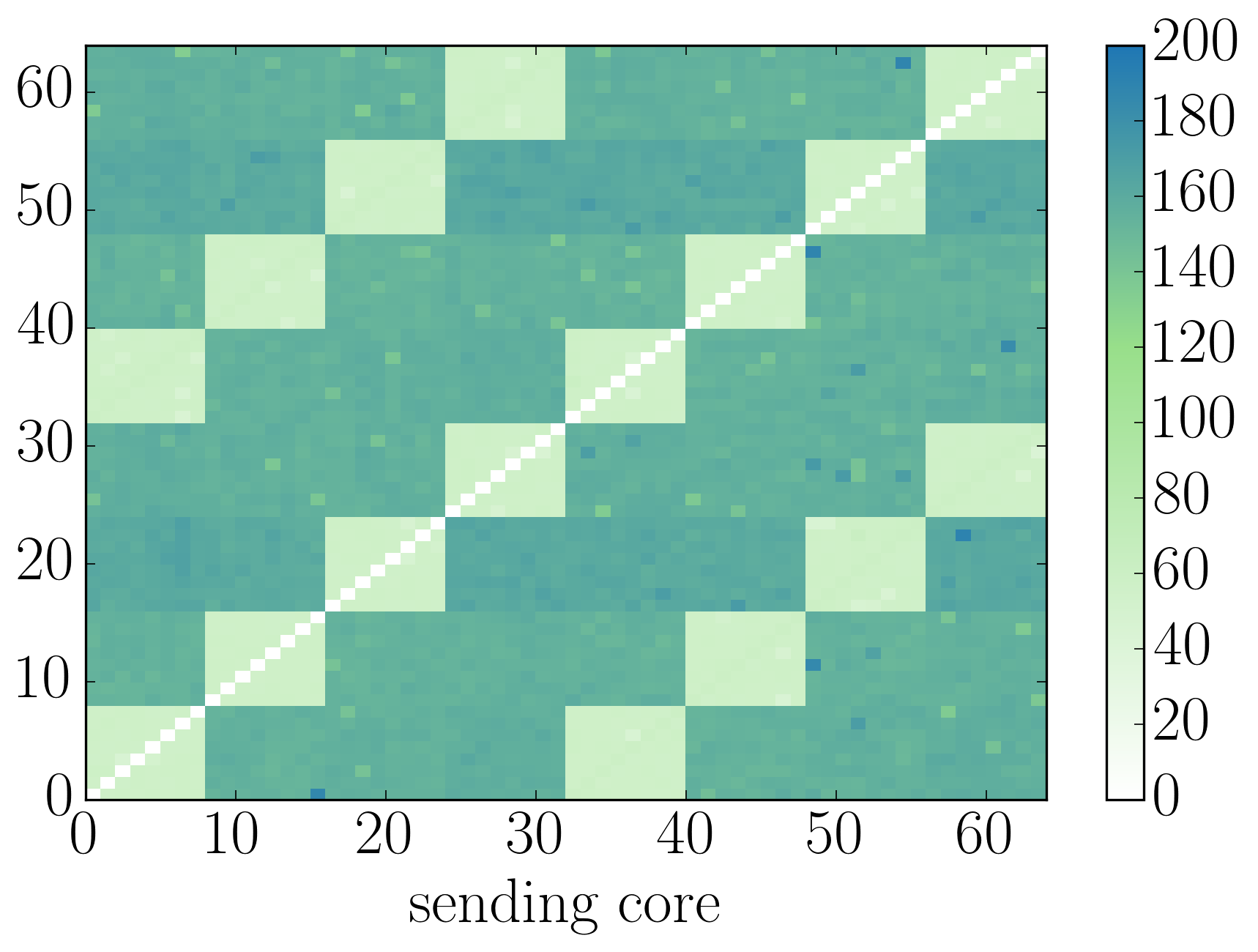
Pairwise Data
The topology information gives us a rough understanding of the expected performance. We complement this with real measurements conducted on the hardware. For this purpose, we use ''pairwise'' a micro benchmark that ping-pongs messages between any combination of cores.
The benchmark measures the send, receive and roundtrip times, i.e. the time it takes until smlt_qp_send() or smlt_qp_recv() return.


Message Passing micro benchmark
A comparison of this benchmark can be found on this page.
We now show the results of our micro benchmarks. For reference, see
bench/ab-bench in the Smelt directory.
Multicast benchmark
A comparison of this benchmark can be found on this page.
We now show the results of our micro benchmarks for multicasts. For
reference, see
bench/ab-bench-scale
in the Smelt directory.
Showing plot ab.
Showing plot reduction.
Showing plot barriers.
Showing plot agreement.
EPCC benchmark
A comparison of this benchmark can be found on this page.
Execution of the EPCC benchmark with gcc's unmodified OpenMP compared to an instance using Smelt's barrier.
Showing plot csv.
Barrier throughput micro-benchmarks (5.4)
A comparison of this benchmark can be found on this page.
We now show the results of our micro benchmarks measuringperformance of multicasts given a round-robin vs. fillingthread to core allocation strategy.
